KilterGPT
Generating Climbs on a Kilter Board with AI

Most of you are likely familiar with this object, but let's introduce it for those who aren't. This is a Kilter board - a highly popular brand of system board. Their standardised design allows climbers across the globe to climb on the same routes, track their progress as gym climbs change, and add their own routes to the ever-expanding collection. The adjustable angle and diverse hold selection make it a fantastic training tool.
I love kilterboarding, so I decided to create an AI model that generates Kilter board climbs.
By the way, I'm Ilya. I'm completing my PhD in Bioinformatics and have a deep passion for climbing, sometimes perhaps to a fault. This blog post aims to introduce you to KilterGPT - a GPT-like model capable of generating the perfect Kilter board climb for you. Let's dive in!
Data Representation
Before exploring the intricacies of attention mechanisms and transformer models, let's examine how climbs are actually loaded into the Kilter board. Take this climb for example ("proj braj" by the incredible Jimmy Webb, 7a+ @ 40°):

It would be stored in the system as p1086r15p1113r15p1145r12p1163r12p1186r13p1198r13p1254r13p1283r13p1353r14.
While this may look like a random string of characters, but it's quite simple to decode.
Each hold is stored as pxxxxryy, where xxxx is the hold's label and yy is its color.
Kilter boards have 4 colors: green for start holds (r12), cyan for handholds (r13), purple for finish holds (r14), and orange for footholds (r15).
The holds range from 1073 to 1599.
So the decrypted climb would look like this:

GPT Models
Now that we understand how climbs are encoded, let's consider how to generate new ones.
The current frontrunners for this task are Generative PreTrained models, commonly known as GPT models.
They're trained on vast text collections with a straightforward objective: given a text of length n, predict the word at position n+1.
This process is repeated for each word in the sequence.
For instance, given the text:
Sorry I forgot about your birthday, I was climbing.
The input -> prediction pairs would look like this:
Sorry I -> forgot
Sorry I forgot -> about
Sorry I forgot about -> your
Sorry I forgot about your -> birthday,
Sorry I forgot about your birthday, -> I
Sorry I forgot about your birthday, I -> was
Sorry I forgot about your birthday, I was -> climbing.
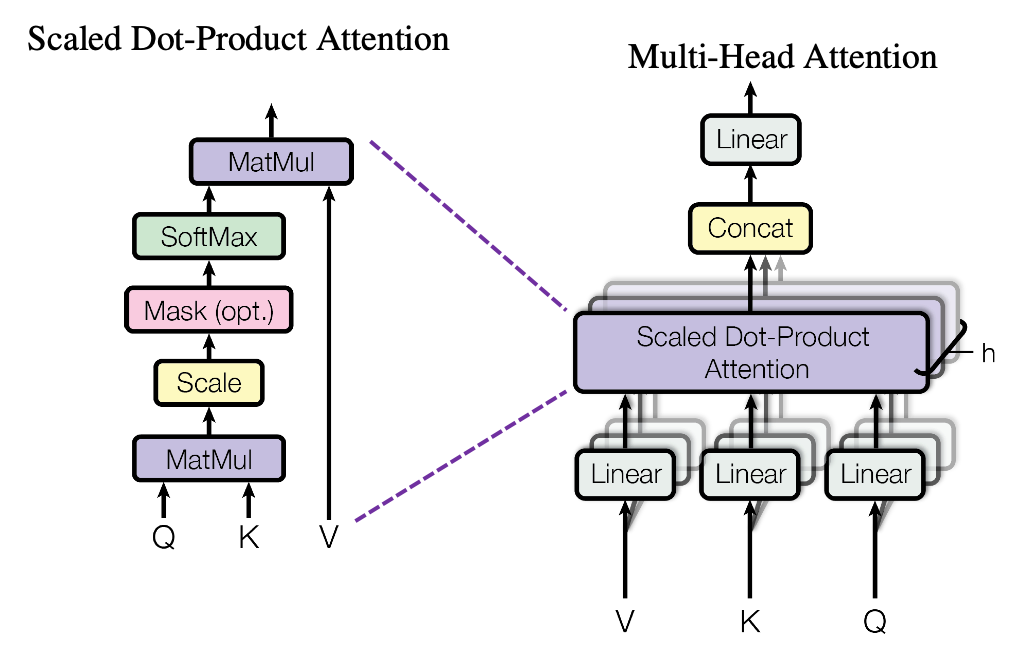
Attention Mechanisms
Most GPT models today employ self-attention mechanisms and transformer architectures. A detailed explanation of self-attention is beyond the scope of this post, but it's important to note that self-attention allows the model to evaluate the importance of all other input parts when making a prediction. For a deeper dive, check out this post which explains attention mechanisms in detail. GPT models use causal attention, meaning they predict tokens based solely on inputs to their left.
KilterGPT
Now that we know how the climbs are encoded for the Kilter board and how GPT models work, let's combine the two to create KilterGPT.
To get started, we need to break down the climb into 'tokens' that the model can understand.. While natural language tokenization for deep learning is complex, Kilter board climb tokenization is refreshingly simple. We create unique tokens for each hold position, color, and some special tokens (padding, beginning of sentence, end of sentence). Then we go through our climb and replace each hold with its token. We also add a special token at the beginning and end of the climb to help the model understand where the climb starts and ends. Thus, the aforementioned "proj braj" climb, would be tokenized into:
[BOS, p1086, r15, p1113, r15, p1145, r12,
p1163, r12, p1186, r13, p1198, r13,
p1254, r13, p1283, r13, p1353, r14, EOS]
Where BOS and EOS signify the beginning and end of the climb, respectively.
Then, each token is assigned a unique ID, so the model can understand them.
The final encoded series of tokens would look like this:
[1, 22, 8, 49, 8, 81, 5,
99, 5, 122, 6, 134, 6,
190, 6, 219, 6, 289, 7, 2]
Angle and grade
Now, let's see how we incorporate the angle of the board and the difficulty of the climb into our model. The kilterboard is designed to be adjustable, with angles ranging from 0 to 70 degrees. So we simply normalize the angle value to be between 0 and 1, and give it to the model alongside the hold sequence.
Representing the climb's difficulty (the grade) presents a slightly more complex challenge. Internally the kilter board database uses a continuous scale from 0 to 40, which roughtly corresponds the a range from 1a to 9c. We convert it to a range between 0 and 1, with 1a being 0 and 9c being 1. Please don't ask me what a 1a looks like on a Kilter board, I have no clue.
So our climb that is a 7a+ @ 40° would become a 0.5897 @ 0.5714, where 0.5897 is the grade and 0.5714 is the angle.
Shuffling and hold order
I wanted the model to accept prompts - requests to generate climbs featuring specific holds. This is challenging since finish holds typically appear at the end of the encoded climb sequence.
My solution was to shuffle the holds before feeding them to the model. So the proj braj climb could be represented as any of the following permutations:
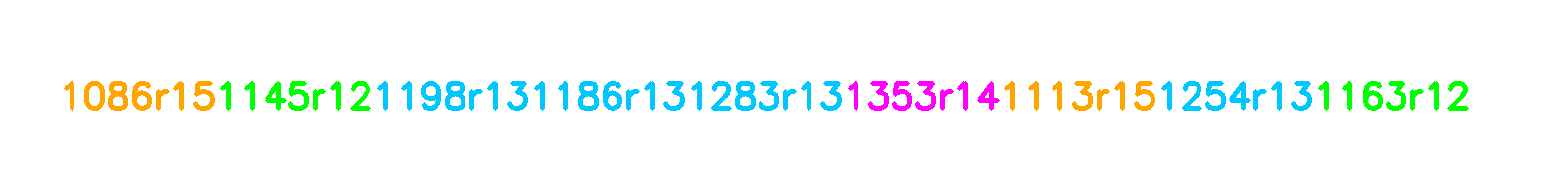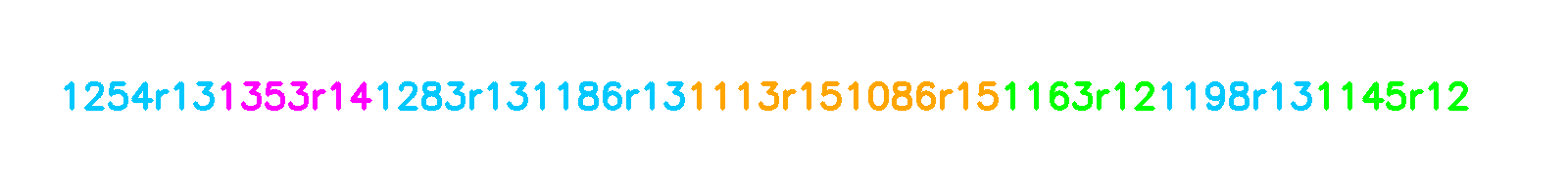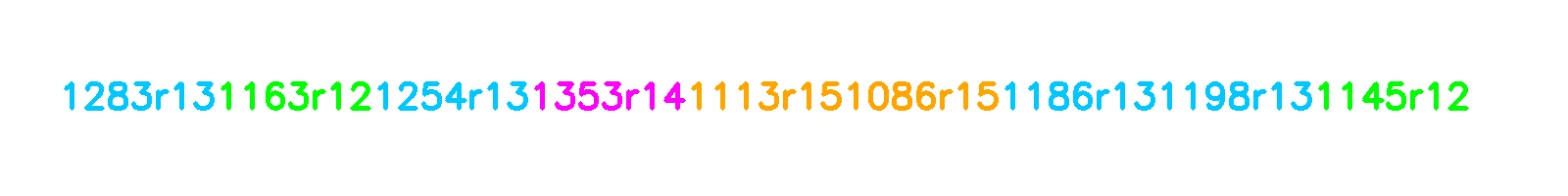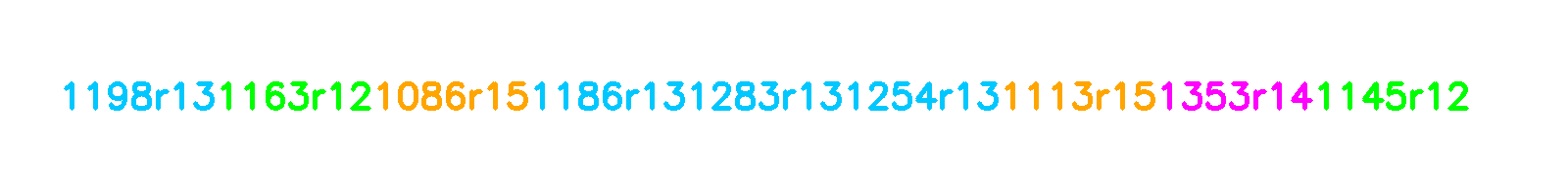
This allows the model to learn to generate climbs from any point, not just from the bottom.
However, shuffling created another issue - the model no longer had a single correct next token. Thus I had to adjust the loss function (how we measure the model's performance).
You can imagine the loss function as the model having correctly guess which token (hold or hold color) is correct at each position. If we visualise this process as a matrix, this becomes akin to playing battleships. This is how the field would look in a normal scenario:
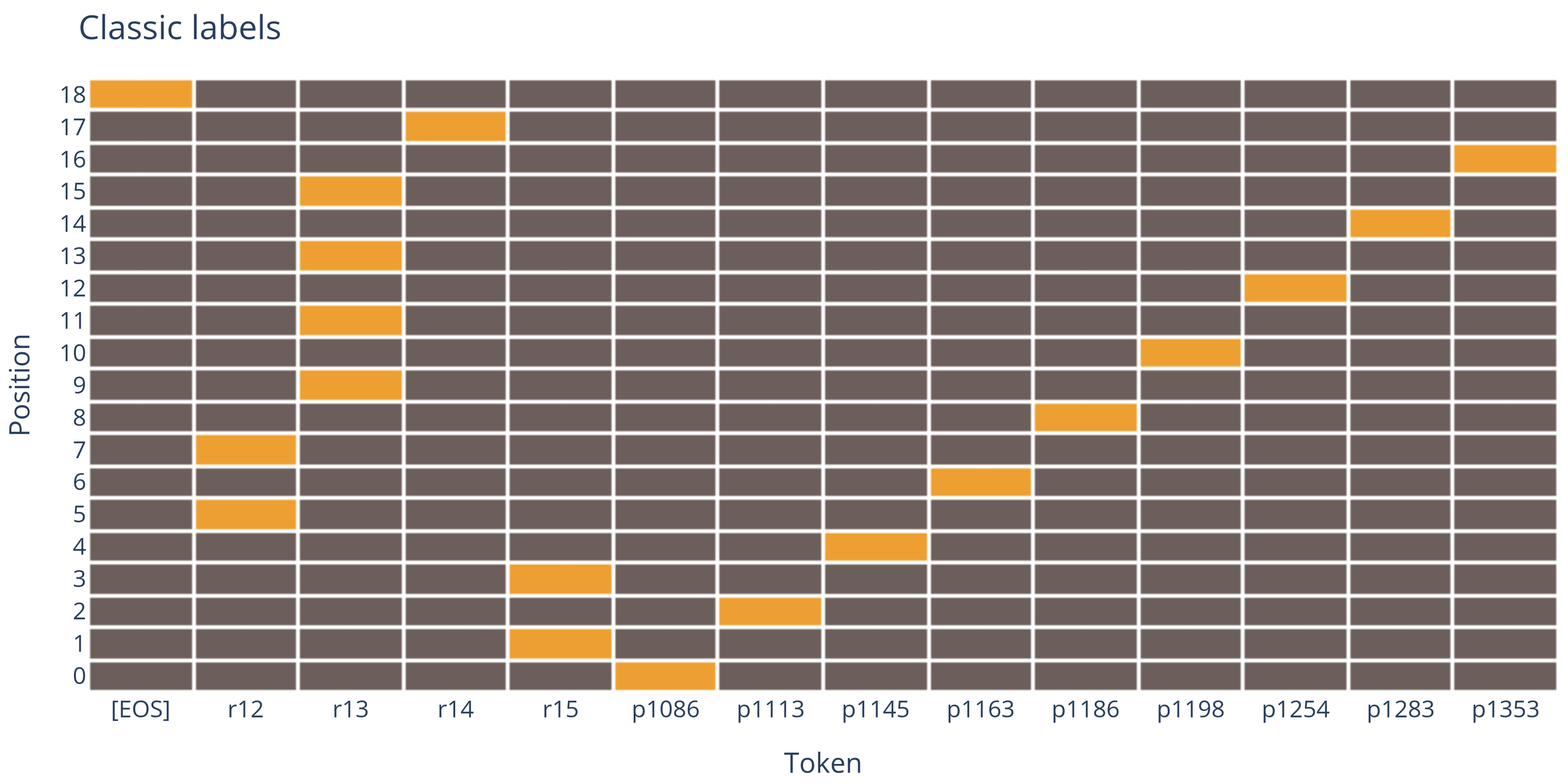
Only one tokens is correct at each position.
Instead of predicting one correct next token, we can allow the model to correctly guess any of the next tokens.
In our example, if the input is p1086r15p1113r15p1145r12p1163r12, the correct next token could be p1186, p1198, p1254, p1283 or p1353.
In our battleships analogy, this would look like this:
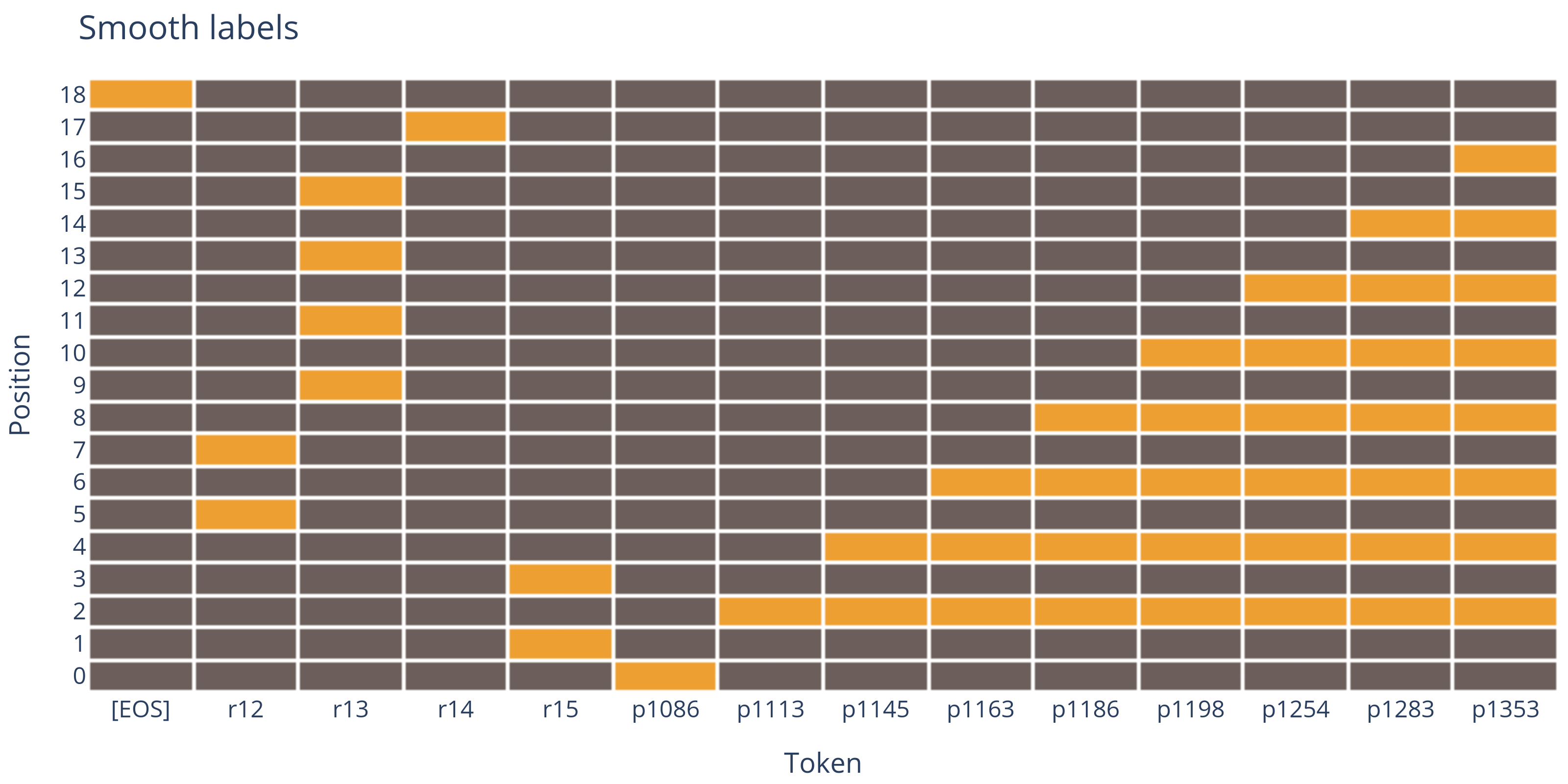
As you can see, this simplifies the model's task tremendously, speeding up training and improving performance.
Training Process
The resulting model is relatively small for a GPT-like model - 35 million parameters. For reference, the latest GPT-3 model has 175 billion parameters. Training took roughly 8 hours on a single Nvidia 3090 GPU, which is quite fast for this size.
Fine-tuning
After training, GPT models are often fine-tuned. For example ChatGPT is first trained for general text generation, then fine-tuned for question answering. KilterGPT is first trained to generate climbs, then fine-tuned to generate good climbs.
This fine-tuning process involves creating a dataset of high-quality climbs and training our model to generate similar climbs.
Climb Generation
Once the model is trained and fine-tuned, we can generate climbs. The process is simple: we give the model a prompt (holds, grade, angle) and ask for a next-token probability distribution. We sample from this and add the token to the input. This repeats until the model generates the EOS token, signaling the climb's end.
We can influence generation with hyperparameters: temperature and top-p sampling. Temperature affects randomness, with higher values leading to more varied climbs. Top-p sampling lets us sample from the top p% of the probability distribution, ignoring holds definitely not needed and focusing on the most likely next token.
Knowing Kilter board climb rules, we can add constraints. For example, every second token is a color, so we restrict the model to r12, r13, r14, r15. We also know there can't be more than 2 start/finish holds, holds aren't repeated, etc.
Here are step-by-step generation visualizations of a 7a+ @ 40° climb (temperature and top-p sampling are set to 0.5):

And here is the generation process for a 7a+ @ 40° climb with temperature and top-p sampling set to 0.9:

As you can see, the higher temperature leads allows the model to choose from more different holds.
Quality Assessment
Once we have a fine-tuned model generating sensible climbs, we need to assess them, looking for diversity and climb quality.
Diversity
We assess climb diversity by comparing generated climbs to real ones using Jaccard similarity - a measure of how similar two sets are. 1 means identical climbs, 0 means no shared holds.
This figure shows how temperature affects the max Jaccard similarity:
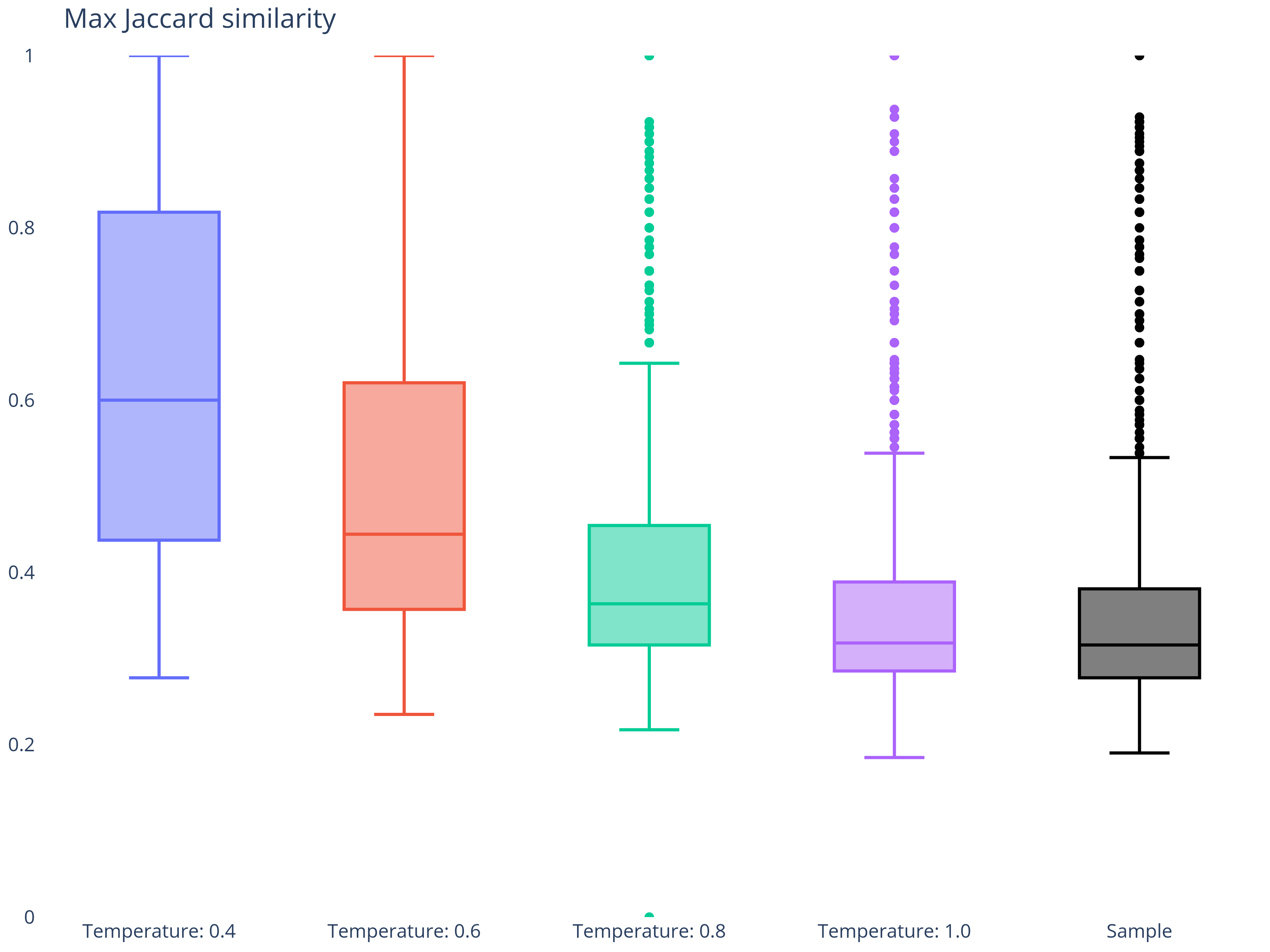
Max similarity is the highest Jaccard similarity between the generated and any real climb, indicating how likely the model is to copy a real climb instead of creating a new one.
Quality
Evaluating the quality of the generated climbs is more subjective. The best assessment is having climbers try them and provide feedback. So please, whenever you try a generated climb, use the like/dislike button to help us improve the model.
Future Directions
We have several ideas for KilterGPT enhancements:
- Generating climbs in specific styles
- Expanding to other boards
- Generating climbs similar to a given climb
- Clustering climbs by style
- And much more!
If you have ideas for improving KilterGPT, please share them!